■ 탐색 알고리즘
BFS, DFS는 그래프를 탐색할 때 사용하는 대표적인 탐색 알고리즘이다. 그래프는 이전 포스팅에서 정리해봤다.
https://yjhdevelopdiary.tistory.com/194
[자료구조] 그래프 (Graph)
■ 의의 현실 세계의 사물이나 추상적인 개념 간의 '연결 관계'를 표현 트리와 굉장히 유사한데 트리보다 약간 넓은 개념으로 보면 됨. 트리가 약간 그래프의 일종이라고 보는게 좀 더 정확할듯.
yjhdevelopdiary.tistory.com
■ DFS (깊이 우선 탐색; Depth First Search)
시작점 기준 뎁스 가장 끝 부분까지 깊이 파고들어서 정보를 추출해주는 알고리즘이다. 막다른 길을 만날 때 까지 뎁스를 늘려 계속 파고드는 원리이다.
[구현 방법]
(1) 재귀 함수
(2) 스택 (Stack) 사용
[코드]
아래 둘 중 하나를 선택해서 인접 정점에 대한 데이터를 생성해줘야한다.

(1) 인접리스트 표현 방법을 택할 시 아래와 같이 작성한다. 재귀 함수 형식으로 작성되어 있고 만약에 누락되어 있는 정점까지 모두 탐색하고 싶을 떄는 정점을 V, 간선을 E라 표현했을 때 평균적인 시간 복잡도는 O(V+E)가 된다.
하지만 최악의 상황은 모든 정점들이 간선으로 이어져 있는 상황인데 그럴 경우 O(V+V^2)가 될 수 있다.


(2) 인접 행렬 표현 방법을 택할 시 아래와 같이 작성한다. 방식은 같으나 코드가 간결해졌다. 하지만 행렬을 사용할 경우 필요없는 메모리 또한 차지하게 되므로 적절한 상황에서 활용해야한다.
누락되는 정점 없이 모든 정점을 탐색하고 싶은 목적을 달성하고자 DFS ALL을 할 경우 시간 복잡도는 O(V^2)가 된다.
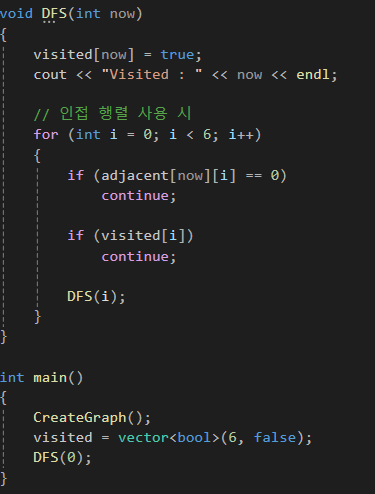

■ BFS (너비 우선 탐색; Breadth First Search)
Entry에서 가장 가까이 있는 순서대로 접근을 하는 방식임. DFS는 말그대로 깊이값에 중심을 두는 것으로 BFS는 너비에 중심을 두는 것임.
즉, 현재 위치에서 먼저 발견한 정점들을 방문하는 것임. '먼저'라는 키워드와 어울리는 것이 Queue 자료구조이므로 이를 사용함.
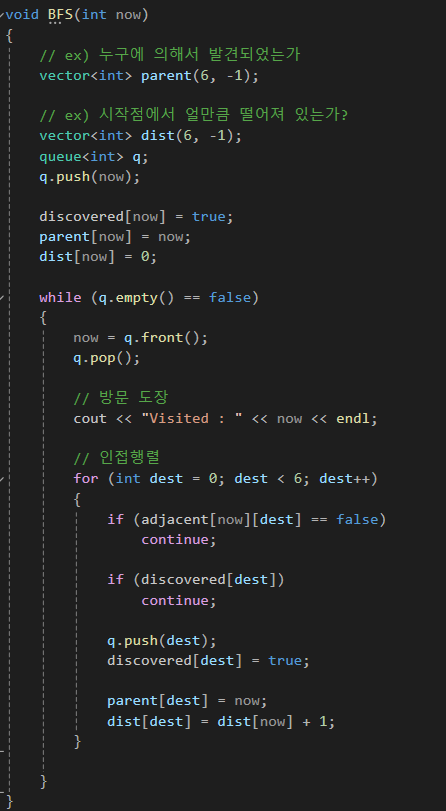
[구현 방법]
(1) 큐 (Queue)
[과정]
(1) DFS에서는 방문한(visited) 목록을 캐싱하는데 BFS에서는 발견한(Discovered) 정점을 캐싱한다.
(2) 큐(queue)를 약간의 예약 시스템이라 생각하고 방문할 예정의 의미로 해당 컨테이너에 인접한 정점들을 추가해준다.
(3) 큐를 pop하면서 (2)를 반복한다.
[코드]


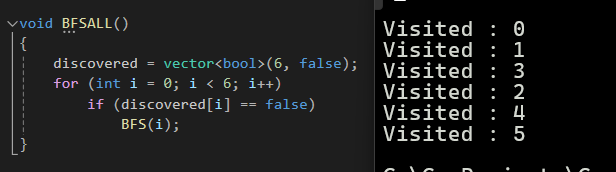
▼ 모든 정점을 대상을 시작점으로 BFS 실행시 (BFS ALL) 아래와 같이 5를 포함한 모든 정점을 방문했다고 표시된다.
[차이점]

참고: (링크)
'Computer Science > Algorithm' 카테고리의 다른 글
| [Algorithm] A* 알고리즘 (0) | 2024.03.29 |
|---|---|
| [Algorithm] 다익스트라(Dijikstra) 알고리즘 (2) | 2024.03.25 |
| [Alogrithm] 히프, 기수, 계수 정렬, 알고리즘 비교표 (1) | 2024.02.07 |
| [Algorithm] 셸, 병합, 퀵 정렬 (0) | 2024.02.07 |
| [Algorithm] 선택 정렬, 버블 정렬, 삽입 정렬 (1) | 2024.02.07 |



