■ 기존 블로그 글
https://yjhdevelopdiary.tistory.com/200
[Modern C++] Unicode, MBCS, WBCS
■ ASCII char는 C++에서 1바이트를 차지한다. unsinged 라면 0~255 사이의 숫자만 표현할 수 있다. 컴퓨터 출시 초기에 작업을 할 때는 미국에서 군사용 목적으로 사용되었고 이때 ASCII코드를 사용했었
yjhdevelopdiary.tistory.com
이전에 C++ 관련 글을 올리면서 Unicode, MBCS, WBCS, ASCII, ANSI에 대해서 간략하게 글을 작성하였었다.
https://yjhdevelopdiary.tistory.com/119
[전자계산] 자료 표현 방식
■ 외부적 표현 방식 code로 표시하여 사람이 이해할 수 있도록 표현한 방식이다. (비트 수 꼭 암기) 종류 설명 BCD code (Binray Code Decimal) IBM에서 제작한 방식. 2진화 10진 코드로 불린다. 6비트로 구성
yjhdevelopdiary.tistory.com
정보처리 준비하면서 작성했던 자료 표현 방식에 덧붙이는 느낌이다.
■ 문자 집합과 인코딩
(1) 문자 집합 (Character Set)
· 컴퓨터가 이해할 수 있는 문자의 모음
(2) 인코딩 (Encoding)
· 문자를 0과 1로 변환하는 과정
(3) 디코딩 (Decoding)
· 0과 1로 표현된 코드를 문자로 변환하는 과정
■ 아스키 코드 (ASCII)
· 초창기 문자 집합 중 하나
· 알파벳, 아라비아 숫자, 일부 특수 문자 및 제어 문자
· 7비트로 하나의 문자 표현: 실제론 8비트이나 최상위 비트는 오류 검출을 위해 사용된다.
이는 패리티 비트(Parity Bit)라고 한다.
■ EUC-KR (한글 인코딩)
· 완성형 인코딩 방식 (조합형 x)
· 글자 하나 하나에 2바이트 크기의 코드 부여
· 2바이트 == 16비트 == 4자리 16진수로 표현

[문제점]
· 2300 개 정도의 한글 표현 가능
· 여전히 모든 한글을 표현하기엔 부족한 수임
· 언어별 인코딩 방식을 다르게 하면 다국어를 지원해야하는 프로그램은 언어별 인코딩 방식을 모두 이해해야함.
■ 유니코드 문자 집합 (UTF-8, UTF16, etc..)
이에 대해선
모든 언어, 특수 문자까지 통일된 문자 집합을 사용하면 어떨까? 하는 의문에서 나온 문자 표현 방식
· 통일된 문자집합
· 한글, 영어, 화살표와 같은 특수 문자, 심지어 이모티콘까지 표현 가능
· 현대 문자 표현에 있어서 매우 중요한 방식임
· 유니코드 문자 집합표에는 "한(D55C), 글(AE00)"과 같이 모든 집합에 16진수 값이 부여되어 있다.
· 코드로 변환할 때 이 값들을 그대로 적용하는 것이 아니라, 변환 방식을 어떻게 하냐에 따라 인코딩 방식이 나뉘게 된다.
· UTF-8, UTF16, UTF-32, etc..
■ UTF-8
· Unicode Transformation Format : 유니코드 인코딩 방법
· UTF-8은 가변 길이 인코딩 : 한 글자당 1~4Byte의 크기를 가짐
· 인코딩 결과는 몇 바이트가 될 지는 유니코드에 부여된 값 따라 나뉘게됨


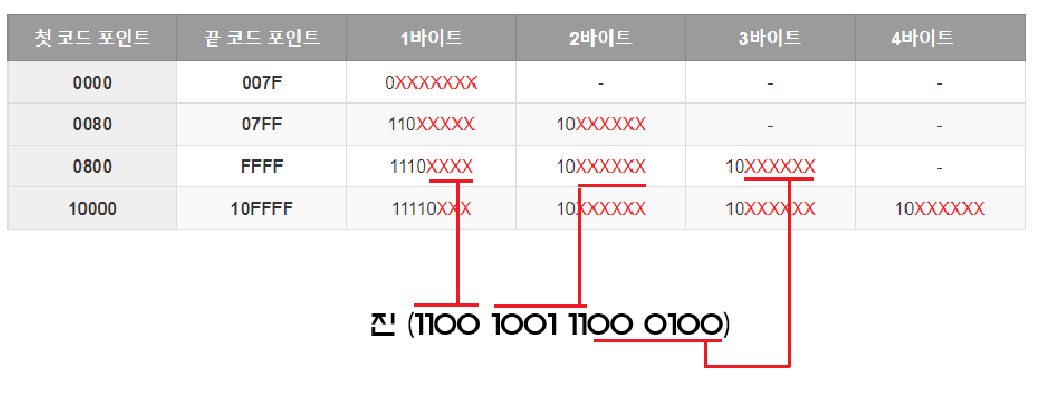
[방식]
· 문자에 부여된 유니코드 값의 범위가 0부터 007F까지는 1Byte
· 문자에 부여된 유니코드 값의 범위가 0080부터 07FF까지는 2Bytes
· 문자에 부여된 유니코드 값의 범위가 0800부터 FFFF까지는 3Bytes
· 문자에 부여된 유니코드 값의 범위가 10000부터 10FFFF까지는 4Bytes로 표현
| 첫 코드 포인트 | 끝 코드 포인트 | 1바이트 | 2바이트 | 3바이트 | 4바이트 |
| 0000 | 007F | 0XXXXXXX | - | - | - |
| 0080 | 07FF | 110XXXXX | 10XXXXXX | - | - |
| 0800 | FFFF | 1110XXXX | 10XXXXXX | 10XXXXXX | - |
| 10000 | 10FFFF | 11110XXX | 10XXXXXX | 10XXXXXX | 10XXXXXX |
(ex)
· 진: C9C4 (1100 1001 1100 0100)
· 현: D604 (1101 0110 0000 0100)
두 글자의 코드 포인트 모두 0800 ~ FFFF 사이에 위치하므로 3Bytes임
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [컴퓨터 구조] 명령어, 주소 지정 방식 (0) | 2024.09.17 |
|---|---|
| [컴퓨터 구조] ALU, 제어 장치 (0) | 2024.09.17 |
| [컴퓨터 구조] 고급언어와 저급언어 (0) | 2024.08.25 |
| [컴퓨터 구조] 0과 1로 표현하는 숫자 (0) | 2024.08.25 |
| [컴퓨터 구조] 핵심 부품, 시스템 버스 (0) | 2024.08.25 |



